Managed AI Inference: Why the Companies Winning with AI Aren't Doing It Alone
A practical guide for IT services firms, MSPs, and non-AI-native companies that want to offer AI capabilities without becoming an AI company
The new reality
Every company is now an AI company. Or at least, every company is supposed to be. Your clients want AI features. Your competitors ship them. The board asks why you aren't.
But here's the thing no one says out loud: most companies using AI today aren't building models. They're not training neural networks. They don't have ML engineers. They don't have GPU clusters.
They're buying inference. They're calling OpenAI, Anthropic, Google, and DeepInfra through an API, getting a response, and passing it to their users. The model is a commodity. The value is in how you wrap it — the routing, the guardrails, the billing, the compliance, the uptime.
And that wrapping? It's where everything goes wrong.
The DIY inference trap
We've seen the same story play out at a dozen companies. A dev team gets excited about AI. They hardcode an OpenAI key into a backend service. It works great in the demo. Then:
- Month 1: The key gets committed to git. Security flags it. Someone rotates it manually and breaks production for 40 minutes.
- Month 2: A client hammers the endpoint. No rate limiting. The $500/month budget burns through in a weekend. Finance wants answers.
- Month 3: OpenAI has an outage. No fallback. The CTO asks "why are we single-provider?" The answer is "because adding Anthropic means rewriting half the integration layer."
- Month 4: Legal discovers there's no audit trail. Who called what model, with what data, and when? Nobody knows. The compliance review stalls.
- Month 6: A new, cheaper model appears. Migrating to it means touching every service that calls the API. Nobody volunteers.
This isn't a technology problem. It's an operations problem. And operations problems don't get solved by writing more code — they get solved by the right operational architecture and the right people running it.
The DIY inference timeline
Based on patterns observed across 12+ IT services engagements
What non-AI-native companies actually need
You don't need an ML team. You don't need to fine-tune a model. You need five things:
- A single endpoint that abstracts away the provider. Your code calls one URL. Routing, failover, and model selection happen behind it.
- Per-client guardrails — spend caps, rate limits, model allowlists — so no one client can blow up your bill or violate your data policy.
- Multi-provider routing that selects the right model for the job (cheap tasks get cheap models, quality tasks get frontier models) and fails over automatically.
- An audit trail — every request logged with model, provider, cost, latency, and client identity. Compliance isn't optional.
- A human who watches it — not just dashboards and alerts, but someone who understands the system, notices when costs drift, when latencies spike, when a new model should replace an old one.
Points 1–4 are software. Point 5 is the one that changes everything.
The MSP model: human-operated AI inference
A Managed Service Provider (MSP) for AI inference is exactly what it sounds like: a team that runs your AI infrastructure for you. Not a SaaS platform you log into and figure out yourself. A team of people who:
- Onboard your clients into the gateway
- Set per-client guardrails based on your business rules
- Monitor costs and alert before budgets are hit
- Rotate provider keys and manage credential lifecycle
- Evaluate new models and migrate clients when better options appear
- Handle incidents — provider outages, unexpected cost spikes, compliance questions
The software does the heavy lifting at request time — sub-200ms auth, routing, and guardrails. The humans do the heavy thinking the rest of the time — capacity planning, cost optimization, security review, and the judgment calls that software can't make.
Software handles the request loop. Humans handle the business loop. Both run continuously. That's the model.
How it works: the Retanu architecture
Retanu is the platform we built for this. It's a multi-tenant, OpenAI-compatible inference platform with real-time guardrails, async telemetry, and a full operator console. Here's the hot path for every request:
Request hot path (no synchronous DB access)
Every step reads from Redis, not Postgres. Config changes propagate in <1s via cache warming.
The operator console gives the human side full visibility:
- Workspace overview: total spend, savings from routing, request volume, active clients
- Per-client detail: usage, logs, guardrail status, API keys, routing config
- One-click onboarding: create a client, set guardrails, issue a scoped API key, hand over the endpoint
- Branded subdomains: your clients call
acme.api.retanu.com, not some generic gateway URL - Live test console: test any client's inference path with streaming output, see model/provider/cost in real time
Operator console — workspace overview
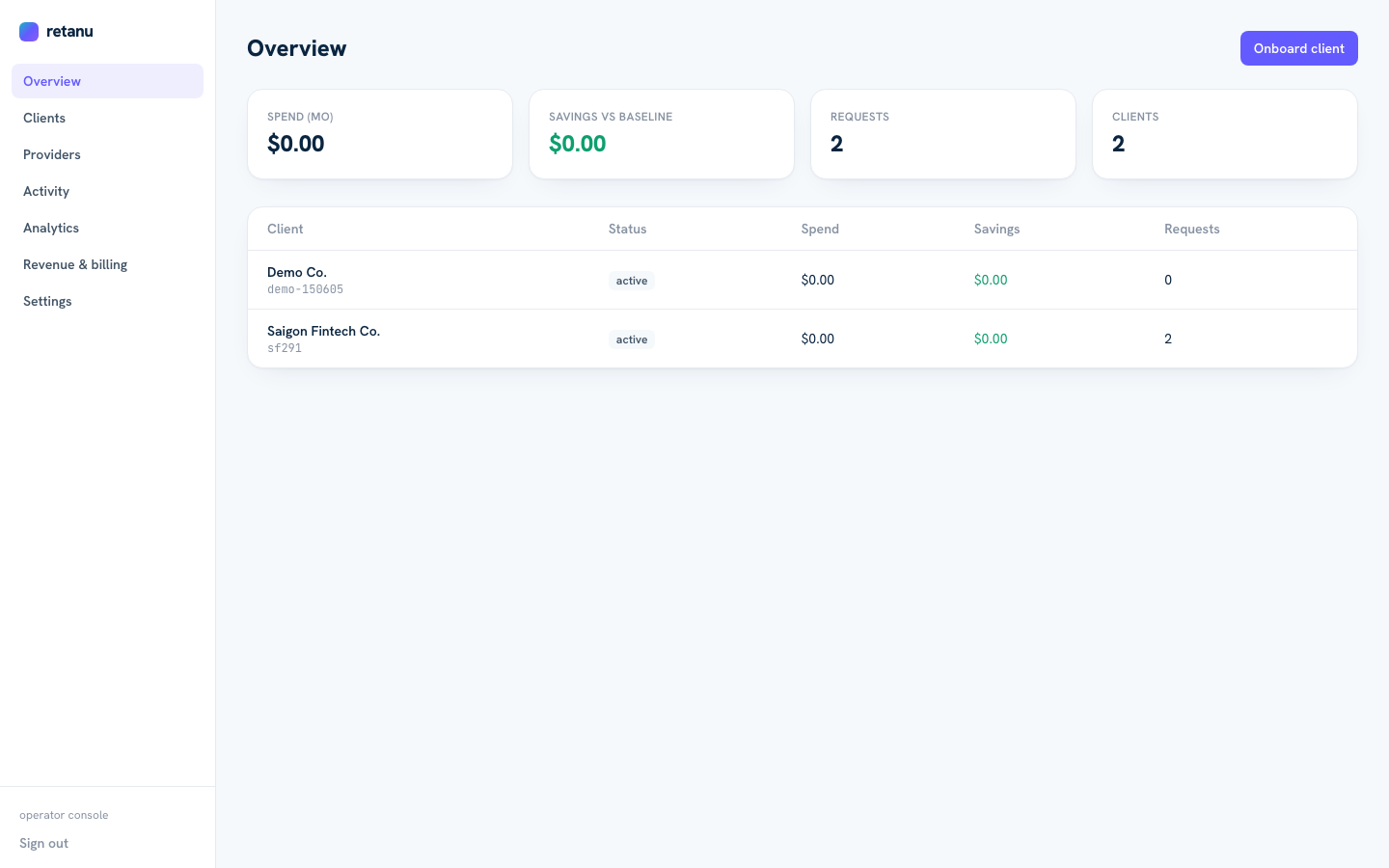
Real-time metrics: spend, savings from smart routing, request counts, and client activity at a glance.
Client detail — per-client configuration & routing
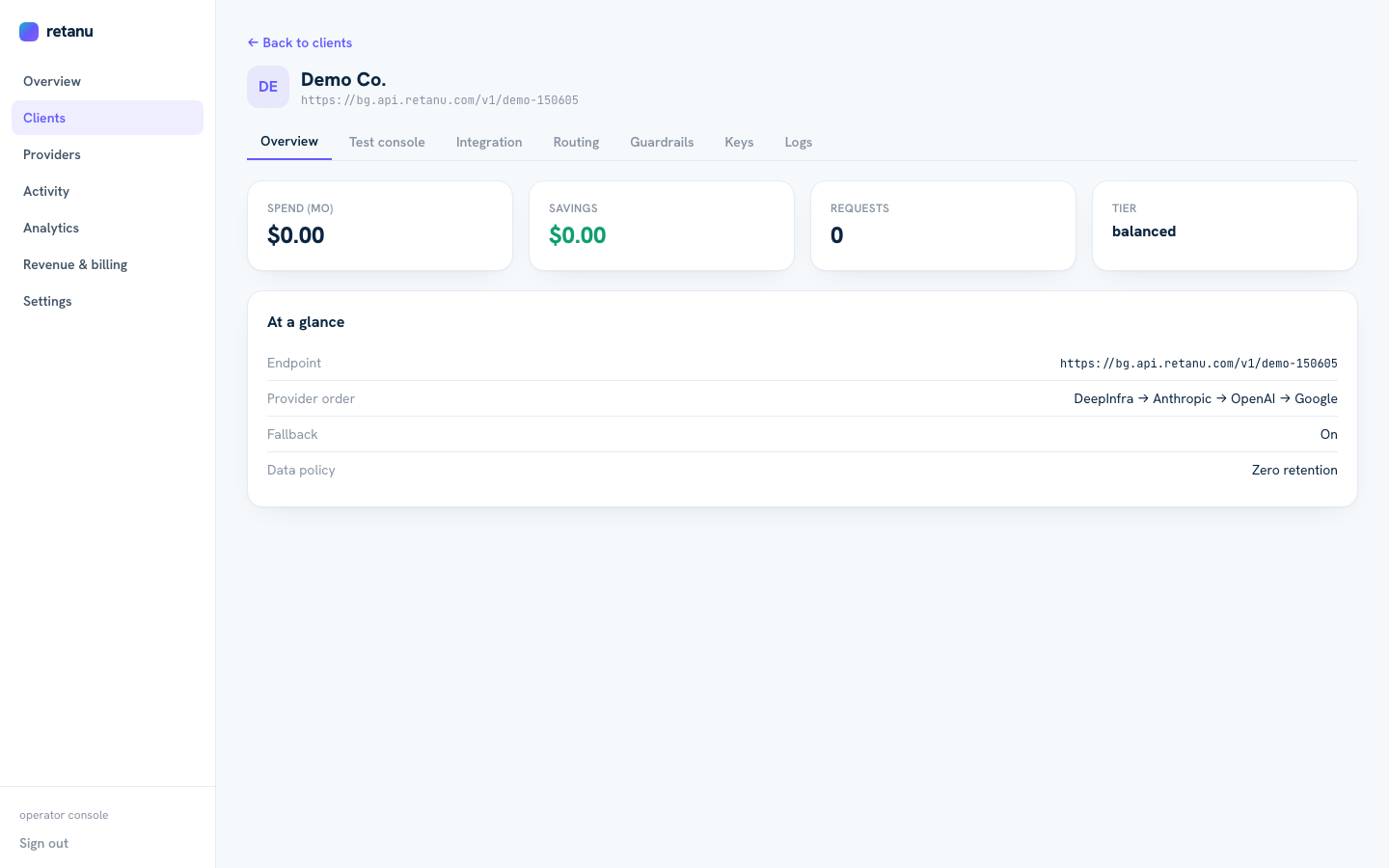
Each client gets a branded endpoint, custom provider order, tier assignment, and scoped API keys.
Live test console — validate inference in real time
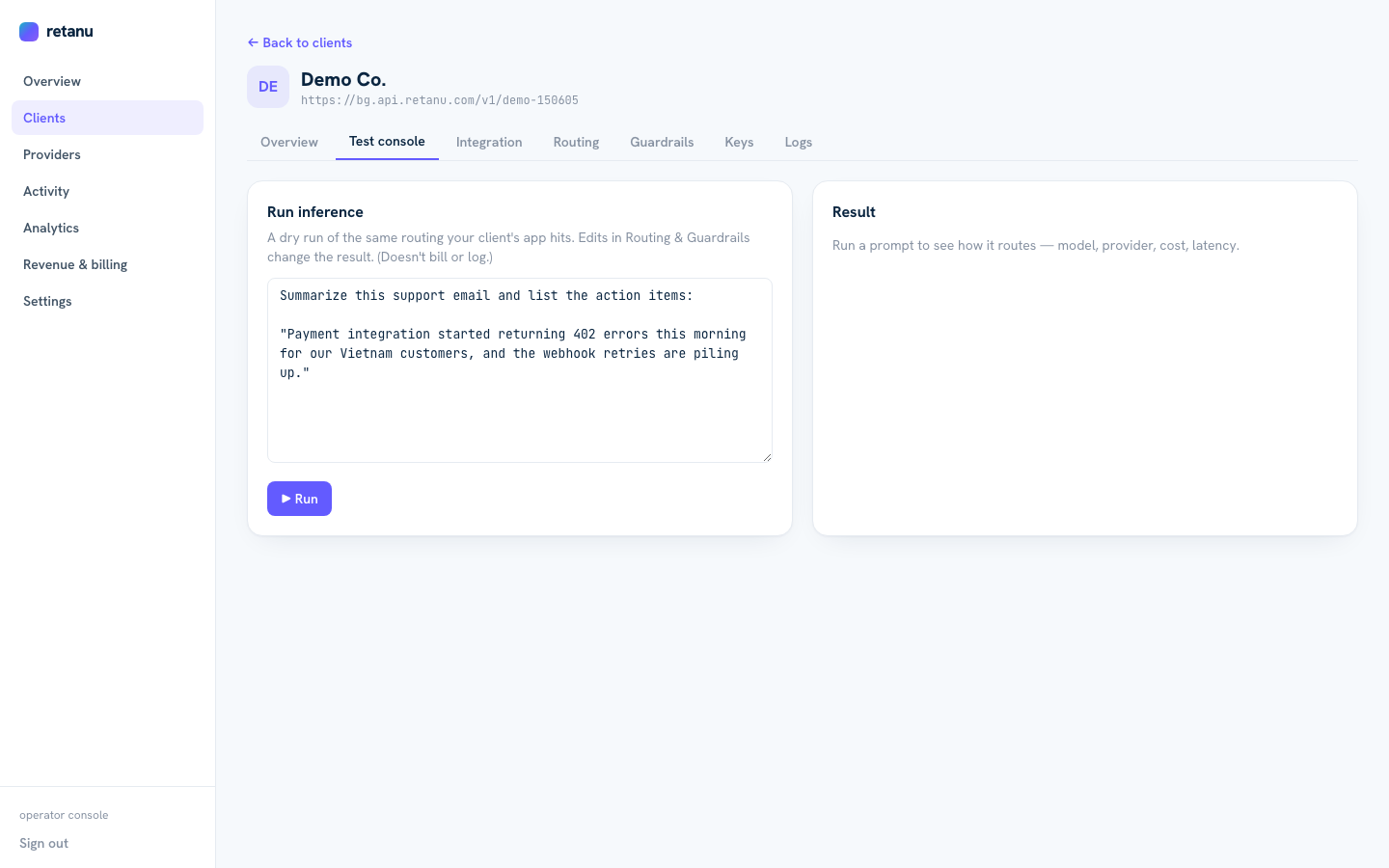
Send a test prompt through any client's inference path. See model selection, provider, cost, and latency live.
What the numbers look like
Here's a real comparison for a mid-size IT services company with 15 clients consuming AI inference:
| Metric | DIY (direct API) | Retanu + human ops |
|---|---|---|
| Monthly provider spend | $12,400 | $8,200 (−34%) |
| Engineering time on AI ops | ~60 hrs/mo | ~8 hrs/mo |
| Provider outage downtime | 2–4 hrs (manual) | <30s (auto-failover) |
| Time to onboard new client | 1–2 days (dev work) | 5 minutes (console) |
| Compliance audit readiness | Weeks of log archaeology | Always — every request logged |
| Model migration effort | Multi-sprint project | Config change, zero downtime |
| Cost visibility per client | None (shared API key) | Per-client, per-model, per-request |
The 34% cost reduction comes from smart routing: cheap tasks (summarization, extraction, classification) go to cost-optimized models; only complex reasoning tasks hit frontier models. Most companies overpay because every request goes to GPT-4 by default.
Cost routing breakdown (15 clients, 1 month)
62% of requests are cheap tasks (summaries, extraction) that cost 12% of total spend. Quality tier handles only 10% of requests but 55% of cost.
Why human ops beats pure automation
You could build all of this as a self-serve platform. Add a dashboard, write some docs, let customers figure it out. Here's why that doesn't work for non-AI-native companies:
They don't know what they don't know
A client calls and says "the AI is slow." Is it the model? The provider? The prompt? The input size? Network latency? A rate limit on the provider side? A human operator checks the telemetry, identifies that the client is sending 8K-token prompts to a model optimized for short inputs, and suggests either a model switch or prompt compression. A dashboard would show "p95 latency: 4.2s" and leave them to guess.
Cost optimization is continuous
New models appear every month. Prices change. A model that was best-in-class in January is overpriced by March. A human operator evaluates new options, runs quality benchmarks on real client workloads, and migrates when the numbers make sense. Automation can alert on cost increases — it can't evaluate whether a new model maintains quality for a specific use case.
Incidents need judgment
When Anthropic has an outage at 3 AM, the gateway auto-fails over to DeepInfra. The request succeeds. But the operator notices the next morning that the fallback model produces slightly different output formatting that breaks one client's JSON parser. The operator adjusts the routing config for that client, adds a schema validation step, and notifies the client. Automation handled the failover. Humans handled the consequence.
Trust requires a face
Non-AI-native companies don't trust dashboards — they trust people. When a CTO asks "is our AI spend under control?", they want to hear it from a person who knows their setup, not read it off a chart. The MSP operator becomes the AI expert that the company doesn't have on staff.
Automation vs. human ops — what handles what
Mid-request failure
Gradual spend increase
Better/cheaper option
New client setup
SOC2, HIPAA readiness
Inside the inference pod: who does what, every day
When we say "human-operated," we don't mean one person checking a dashboard once a week. Retanu's managed inference runs on a dedicated six-person pod — a tight, cross-functional team that treats your AI infrastructure like a production system, because it is one.
The inference pod — six roles, one mission
AI Engineer
The AI engineer is the model brain of the pod. Their daily work:
- Morning model check: Review overnight inference logs. Flag any quality regressions — a model that started returning shorter answers, a provider that bumped latency, a new model version that changed output formatting.
- Provider landscape scan: New models drop constantly. The AI engineer maintains a running eval sheet — testing new releases against real client workloads to see if they're cheaper, faster, or better. When one is, they build the migration case.
- Routing tier calibration: Which tasks are "cheap tier" vs. "quality tier"? The AI engineer adjusts classification rules based on real usage data. A task that was routed to GPT-4o might work just as well on Qwen3-32B at 1/10th the cost.
- Client-specific tuning: One client needs JSON output with strict schemas. Another needs creative long-form text. The AI engineer configures model parameters, temperature, and provider preferences per client.
- Quality benchmarking: Runs structured evals against client workloads whenever a model is added, updated, or swapped. Tracks accuracy, formatting compliance, and response consistency across providers.
Prompt Engineer
The prompt engineer is where most of the cost savings actually come from. Their daily work:
- Prompt audits: Reviews high-spend clients' prompt patterns. Identifies bloated system prompts, redundant instructions, and unnecessarily verbose few-shot examples that burn tokens.
- Token reduction: Rewrites prompts to get the same output quality with 20–40% fewer tokens. A 4K-token system prompt that can be compressed to 2K saves real money at scale.
- Template library: Maintains a shared library of optimized prompt templates for common tasks — summarization, extraction, classification, code generation. Clients get battle-tested prompts instead of reinventing them.
- Output formatting: When a client needs JSON, markdown, or structured output, the prompt engineer designs the prompt and schema constraints that get consistent results across different models.
- Model-specific adaptation: Different models respond differently to the same prompt. The prompt engineer maintains model-specific prompt variants so routing tier changes don't break output quality.
Tech Lead
The tech lead owns the platform codebase and the operator console. Daily work:
- Feature development: New guardrail types, routing strategies, console features, API extensions. The platform evolves continuously based on what operators and clients need.
- Code review and security: Every change to the hot path — auth, routing, guardrails — gets reviewed with a security lens. API key handling, rate limit bypass attempts, input sanitization.
- Architecture decisions: Should we add WebSocket support for streaming? Should the cache warming interval change? Should we split the gateway into regional instances? The tech lead makes these calls.
- Onboarding automation: Building wizard flows, improving the console UX, automating repetitive setup steps so operators can onboard a client in minutes, not hours.
- API compatibility: Keeping the OpenAI-compatible surface area current as upstream APIs evolve — new parameters, new model capabilities, new response formats.
Solutions Engineer
The solutions engineer is the client-facing technical bridge. Their daily work:
- Client integration: When a new client's backend doesn't quite fit the API shape, the solutions engineer guides their dev team through integration — code examples, SDK setup, webhook configuration.
- Onboarding calls: Walks new clients through their first API call, explains rate limits and guardrails, sets expectations on model behavior and latency.
- Migration planning: Client moving from direct OpenAI to Retanu? The solutions engineer maps their existing calls, identifies breaking changes, and builds a migration runbook.
- Custom configuration: Some clients need non-standard setups — IP allowlisting, custom headers, specific failover preferences. The solutions engineer translates business requirements into gateway config.
- Feedback loop: Sits between clients and the rest of the pod. "Three clients asked for usage webhooks this month" becomes a feature request with real context.
Infra Lead
The infra lead keeps everything running. This is the person who sleeps with PagerDuty on. Daily work:
- Health monitoring: Gateway response times, Redis memory usage, Postgres connection pool saturation, provider API health. If p99 latency crosses 3s, they know before the client does.
- Deploy pipeline: Zero-downtime deploys of gateway updates. Blue-green rollouts, database migrations, cache invalidation. Nothing ships without a rollback plan.
- Scaling decisions: Traffic spikes when a client launches a new feature. The infra lead pre-scales based on client notifications, or auto-scales based on request volume and CPU.
- Incident response: Provider outage? The auto-failover handles the request path. The infra lead handles everything else — status page update, client notification, post-mortem, and config adjustment to prevent repeat impact.
- Cost infrastructure: Right-sizing the gateway instances, optimizing Redis memory, managing Postgres vacuuming and index health. Infra costs are real — keeping them lean keeps margins healthy.
- Backup and disaster recovery: Nightly Postgres snapshots, Redis persistence config, cross-region failover planning. The boring work that matters when things go wrong.
QA Engineer
The QA engineer is the last line of defense before anything touches a client. Daily work:
- End-to-end test runs: Every morning, the full test suite runs against the staging gateway — auth flows, guardrail enforcement, rate limiting, provider failover, streaming responses. Failures block deploys.
- Client integration validation: When a new client onboards, QA runs their specific integration flow end-to-end. Does the key authenticate? Does the model route correctly? Does the response format match what their parser expects?
- Regression catching: A new model version outputs markdown where the old one output plain text. A routing change sends cheap-tier requests to a provider that's 200ms slower. QA catches these before clients do.
- Guardrail testing: Spend caps, rate limits, model allowlists — QA actively tries to break them. Send 1,000 requests in a burst. Exceed the spend cap. Request a model that's not on the allowlist. If the guardrail doesn't hold, it gets fixed before it matters.
- Load and chaos testing: Periodic load tests to validate scaling. Simulated provider failures to verify failover. DNS cutover drills. The QA engineer's job is to break things safely so they don't break unsafely.
Six people. Not sixty. The pod is small by design — tight communication, fast decisions, shared context. Everyone knows every client, every provider, every quirk. That's how you run ops that actually work.
The branded experience
One detail that matters more than people expect: your clients should never see someone else's brand.
With Retanu, the MSP operator claims a branded subdomain — say, acme.api.retanu.com. Every client endpoint becomes https://acme.api.retanu.com/v1/northstar/chat/completions. The client calls your domain. The dashboard shows your logo. The API keys carry your prefix.
From the client's perspective, they're using your AI service. They don't know or care that requests route through four different providers depending on task type and cost tier. They see one endpoint, one bill, one support contact.
This is how non-AI-native companies become AI companies — without hiring a single ML engineer.
Settings — branded subdomain configuration
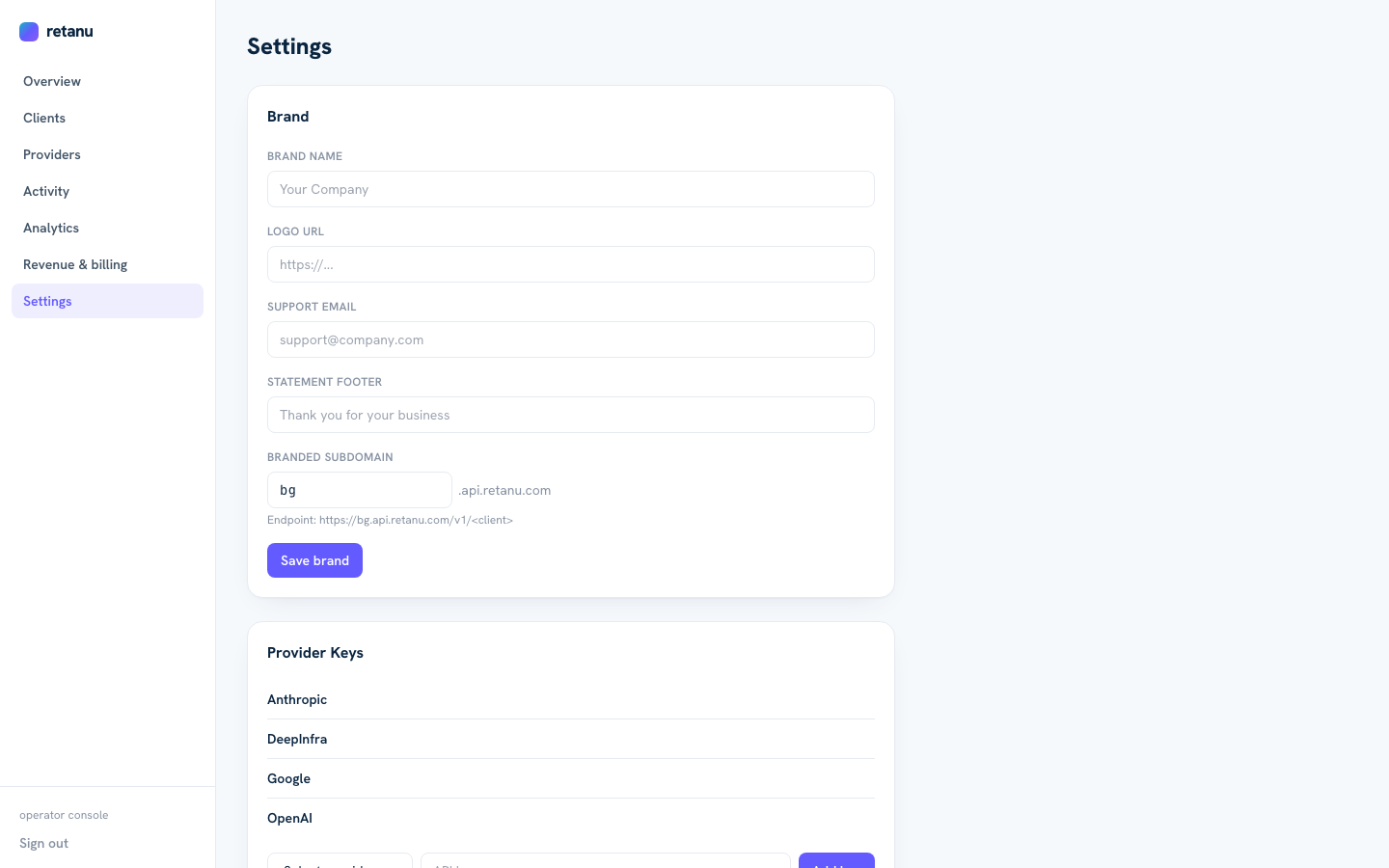
Claim your subdomain in settings. Your clients see your brand, not ours.
# Your client's integration — simple, branded, yours
curl https://acme.api.retanu.com/v1/northstar/chat/completions \
-H "Authorization: Bearer rtn_live_northstar_..." \
-H "Content-Type: application/json" \
-d '{
"messages": [{"role": "user", "content": "Summarize this contract"}]
}'
# Response: standard OpenAI format + cost metadata
{
"model": "Qwen3-32B",
"choices": [{"message": {"content": "The contract stipulates..."}}],
"x_retanu": {
"provider": "DeepInfra",
"tier": "balanced",
"cost_usd": 0.0003,
"latency_ms": 1240
}
}Why OpenAI-compatible matters
This is one of those details that sounds like a checkbox feature but is actually a strategic decision that changes everything about adoption.
OpenAI's API format — /v1/chat/completions with the standard request and response shape — has become the de facto standard for LLM integration. Every major framework speaks it: LangChain, LlamaIndex, Vercel AI SDK, Cursor, Continue, and thousands of custom apps. When your inference platform is OpenAI-compatible, you inherit the entire ecosystem for free.
Zero migration cost
Your client swaps one base URL and one API key. That's it. No new SDK, no code rewrite, no testing cycle. Their existing openai.ChatCompletion.create() call works identically — except now it routes through Retanu with multi-provider failover, per-client guardrails, and cost optimization happening behind the scenes. That's the "5 minute onboarding" claim in practice.
Provider abstraction without lock-in
Behind that single OpenAI-shaped endpoint, Retanu routes to Anthropic, Google, DeepInfra, or OpenAI depending on the task type and cost tier. The client doesn't know or care which provider served the response. If you used a proprietary API format, every provider would need a translation layer and the client would be locked to your format — defeating the purpose of a multi-provider gateway.
Ecosystem compatibility
Any tool that has an "OpenAI base URL" field — and most do — works instantly with Retanu. That's a massive surface area of potential users who can adopt without writing a single line of code. LangChain agents, Cursor IDE, custom chatbots, RAG pipelines — they all just work.
Lower sales friction
For MSPs selling to non-technical clients, "just change the URL" is a much easier conversation than "integrate our custom API." For enterprise buyers, it means no vendor lock-in — they can always point the URL back to OpenAI directly if they want to. That lack of lock-in, paradoxically, makes them more willing to adopt.
OpenAI-compatible isn't a feature. It's a distribution strategy. Every existing integration is a warm lead.
Who this is for
This model — managed inference with dedicated human ops — is specifically designed for:
- IT services firms and MSPs that want to add AI capabilities to their client offerings without building an AI team
- SaaS companies integrating AI features but don't want to own the inference infrastructure
- Healthcare, fintech, and regulated industries where audit trails and per-client isolation aren't optional
- Agencies and consultancies that build AI-powered products for clients and need per-client billing and guardrails
- Any company with 5+ clients consuming AI where managing API keys, costs, and compliance across all of them is becoming a full-time job
If you have one app calling one model, you don't need this. If you have dozens of clients, multiple models, and a compliance requirement, you do.
What it takes to get started
The setup is deliberately simple:
- Deploy the gateway (Docker image, runs on any cloud). Or we host it.
- Add your provider keys — OpenAI, Anthropic, DeepInfra, Google. Bring your own keys; the gateway stores them encrypted and scoped.
- Onboard clients through the operator console. Set tier, guardrails, rate card. Issue a scoped API key.
- Hand the client their endpoint. They integrate against the OpenAI-compatible API. Drop-in replacement.
- A human operator monitors, optimizes, and supports. That's the part that makes the difference.
Total time from zero to first client in production: about an afternoon.
Integration tab — drop-in code for your clients
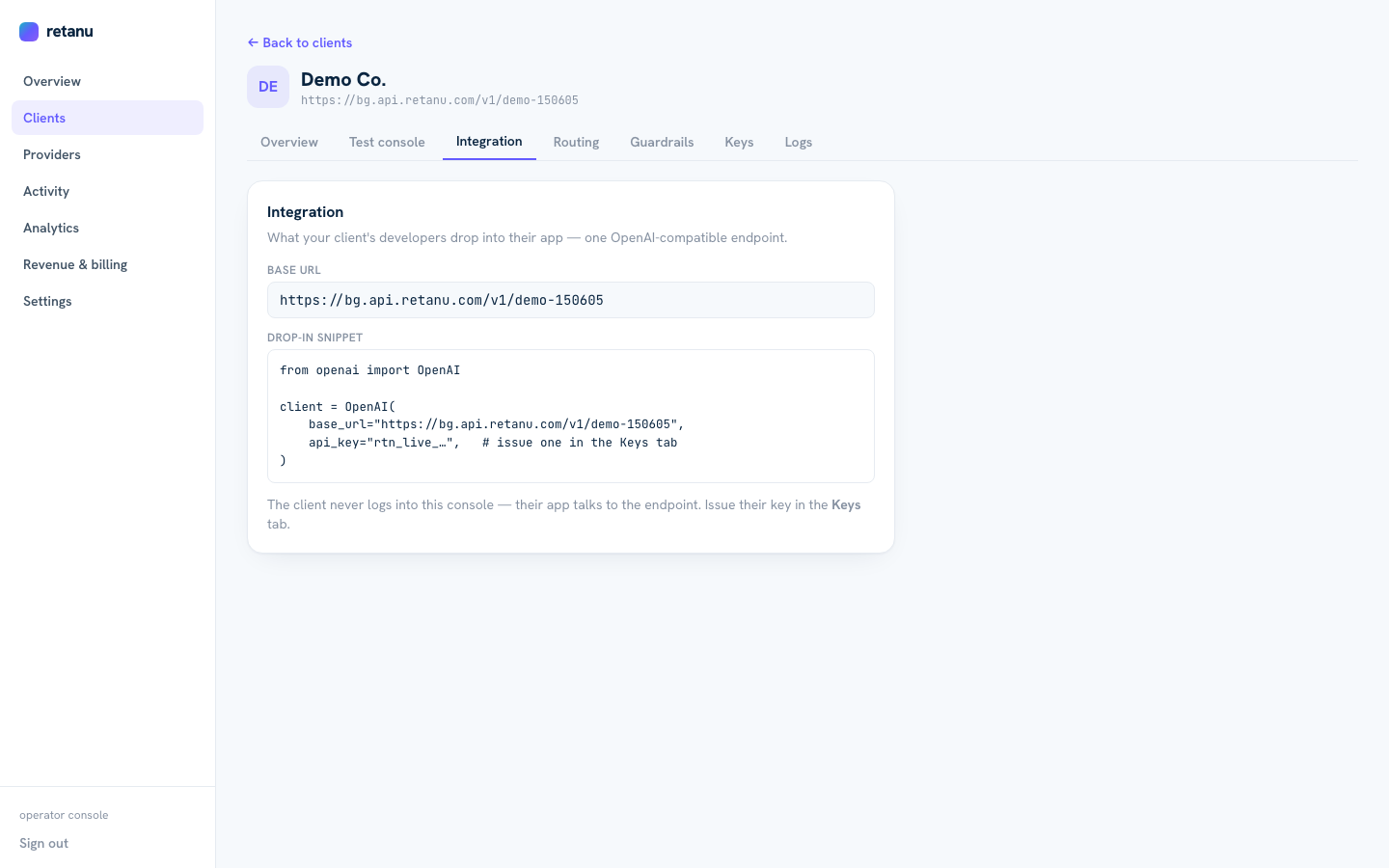
Copy-paste integration code. OpenAI-compatible — clients swap one URL and they're live.
The bottom line
AI inference is becoming a utility. Like electricity, most companies shouldn't generate their own. They should buy it from someone who runs it well, wraps it in the right guardrails, and keeps the bill predictable.
The companies that are winning with AI aren't the ones with the biggest ML teams. They're the ones with the best operational model — the right software handling the request loop, and the right humans handling everything else.
That's what managed inference is. That's what Retanu makes possible. And for companies that aren't AI-native, it's the fastest path from "we should use AI" to "AI is making us money."